N1.02: Section 1
Section 1: Bell-shaped curves—Normal distribution models
It is often useful to model how some property is distributed among a collection of objects that are similar but not exactly alike. Such models are the mathematical answers to questions such as How tall are college students, to the nearest inch? or If you weigh soda cans to the nearest gram, how many have each weight? One good way to answer these questions is to fit a smooth model to data telling how many items have each value. Very often such a model will be close to the bell-shaped curve that mathematicians call a “normal” distribution because it usually results when many independent effects are combined.| A typical application of normal models is the distribution of demographic information | |
Normal-curve model for heights to the nearest inch
parameters: total =13,379, average = 5'10", width = ±3"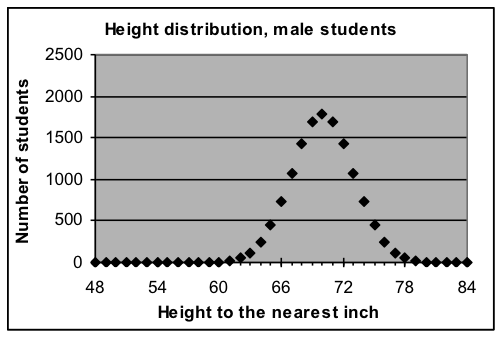 Formula used: =13379*NORMDIST(A3,70,3,FALSE) Formula used: =13379*NORMDIST(A3,70,3,FALSE) |
Normal-curve model for heights to the nearest inch
parameters: total =16,708, average = 5'5", width = ±3"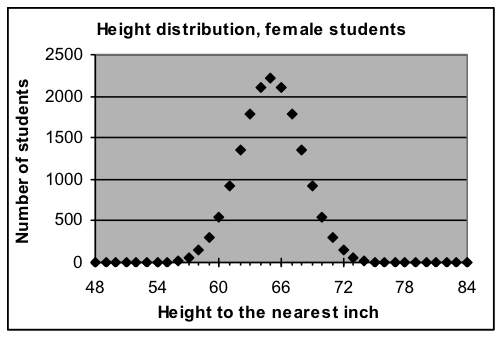 Formula used: =16708*NORMDIST(A3,65,3,FALSE) Formula used: =16708*NORMDIST(A3,65,3,FALSE) |
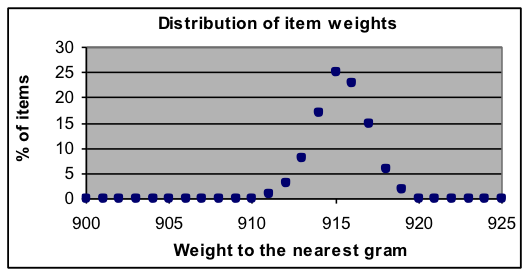
| Example 1: Distribution of weights in a manufactured product The exact weight of standard manufactured products often varies slightly due to small random changes in the machinery that makes them. Measurements of how the weights of a large test sample of individual items are distributed provides information about how dependable the declared weights are. The dataset to the right shows the percentage breakdown of measurements rounded to the nearest gram for a product whose intended weight is 915 grams (about 2 pounds). [a] Fit a normal-curve model to this data and report the parameters found. [b] Do you think that it is accurate for the manufacturers to put a statement on the package of this item that says “Weight 915 grams”? Why or why not? [c] Can you think of way to describe this weight distribution using two numbers that is more informative that just stating the average? |
|
| A | B | C | D | E | F | G | H | |
| 1 | Weight | Percent | y model | Residual | Squared | |||
| 2 | (grams) | of total | prediction | deviation | Deviation | Normal-curve parameters | ||
| 3 | 911 | 1 | 0.542948 | 0.457052 | 0.208897 | 915.3682 | Average | |
| 4 | 912 | 3 | 2.575238 | 0.424762 | 0.180423 | 1.576364 | Width | |
| 5 | 913 | 8 | 8.167791 | -0.167791 | 0.028154 | 99.76079 | Total | |
| 6 | 914 | 17 | 17.32288 | -0.322883 | 0.104253 | |||
| 7 | 915 | 25 | 24.56767 | 0.432333 | 0.186911 | Model and data value counts | ||
| 8 | 916 | 23 | 23.29893 | -0.298926 | 0.089356 | 3 | Number of parameters | |
| 9 | 917 | 15 | 14.77529 | 0.224708 | 0.050494 | 9 | Number of dev. averaged | |
| 10 | 918 | 6 | 6.265626 | -0.265626 | 0.070557 | |||
| 11 | 919 | 2 | 1.776729 | 0.223271 | 0.04985 | Goodness of fit of this model | ||
| 12 | 0.968896 | Sum of squared dev. | ||||||
| 13 | 0.401849 | Standard deviation | ||||||
Licenses & Attributions
CC licensed content, Shared previously
- Mathematics for Modeling. Authored by: Mary Parker and Hunter Ellinger. License: CC BY: Attribution.
